De Illusie van Kant-en-klare AI: Waarom Enterprise Voice Agents Strikte Schema's Vereisen — AssistYou

Door Bram van Zanten, CEO van AssistYou
De kernuitdaging bij het bouwen van enterprise-grade spraak-AI is het beheersen van een paradox. Aan de ene kant wil je een natuurlijke, menselijke gesprekservaring bieden. Aan de andere kant moet je absolute, compromisloze controle behouden over de datastroom binnen je organisatie.
Op dit moment heerst er een gevaarlijke misvatting in veel directiekamers: dat je simpelweg een Large Language Model (LLM) kunt nemen, het aan je bedrijfs-API’s kunt koppelen en het kunt inzetten voor klantenservice.
In een testomgeving ziet dit eruit als magie. In productie is het een risico.
Standaard begrijpen LLM’s de operationele kaders van jouw organisatie niet. Als je betrouwbare, veilige en schaalbare prestaties wilt, kun je niet vertrouwen op het standaard redeneergedrag van het model. Je moet de grenzen zelf ontwerpen.
Bij AssistYou hebben we dit bereikt door onze volledige architectuur te bouwen rondom het concept van het Schema.
Wat is het Schema?
Zie het schema als een strak geoptimaliseerde dialoogblauwdruk. Onder de motorkap is het een complex JSON-bestand dat precies bepaalt waar de AI-agent gespreksvrijheid heeft en waar het strikt wordt begrensd.
Elke agent die wij bouwen werkt binnen deze vooraf gedefinieerde schema’s. Het is de laag die tussen de conversationele AI en je backendsystemen zit en ervoor zorgt dat menselijke onvoorspelbaarheid nooit je bedrijfslogica doorbreekt.
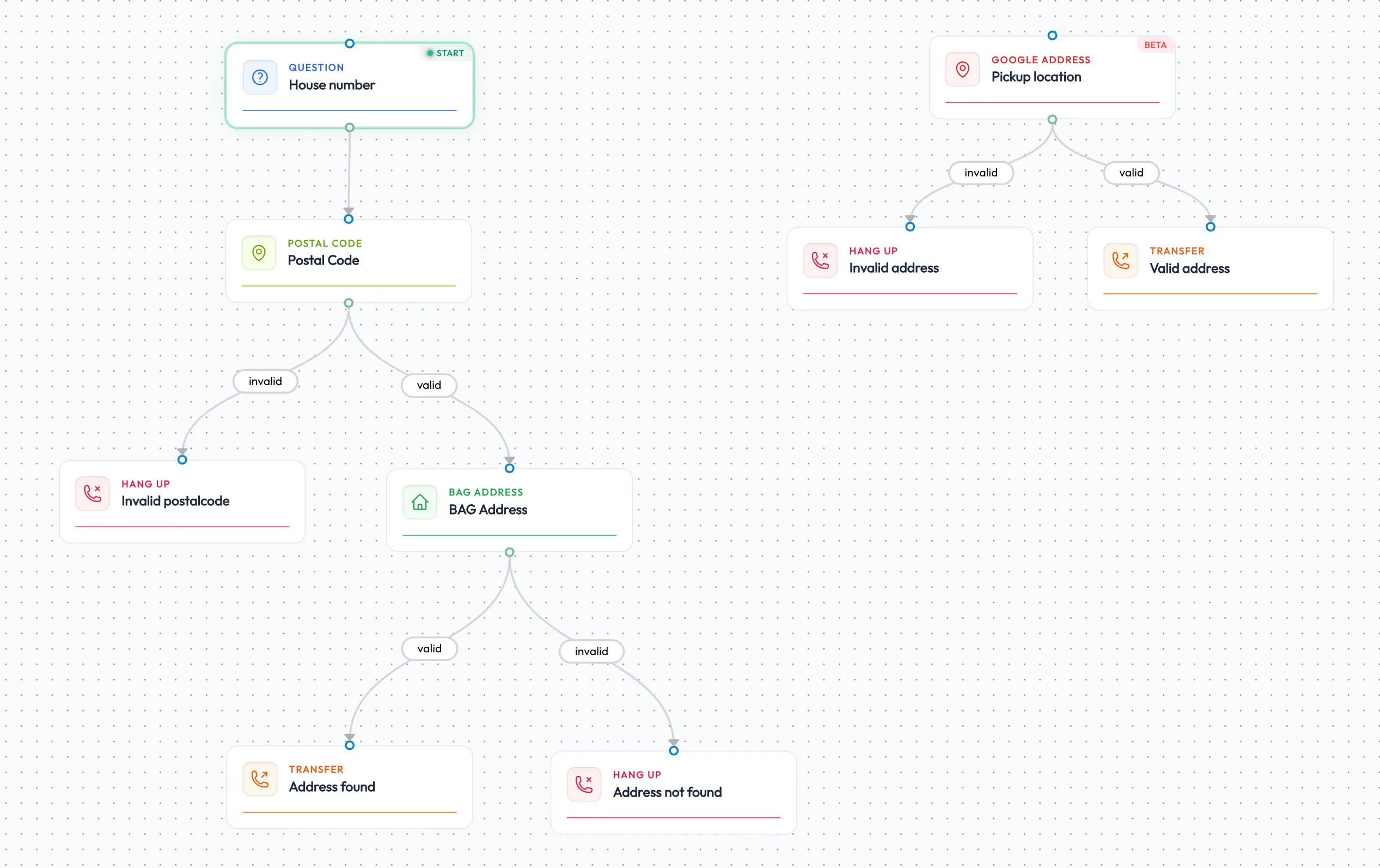
Context Bepaalt de Regels: Integratie met de Geovalidatie-API
Een voice agent kan niet werken met een universele set regels, omdat verschillende sectoren totaal andere niveaus van controle vereisen. Het schema stelt ons in staat om die specifieke spelregels te definiëren, vaak gekoppeld aan een centrale geovalidatie-API die locatiegegevens nauwkeurig verwerkt op basis van de behoeften van de sector.
Het Utility-paradigma: Als je een energiebedrijf bent dat een adreswijziging verwerkt, is het proces strikt. De agent mag niet gokken of vage oriëntatiepunten accepteren. Het schema dwingt een strikte lookup af via de geovalidatie-API, waarbij een gestructureerde, geverifieerde straatnaam en huisnummer worden vastgelegd voordat het proces verder gaat.
Het Mobiliteitsparadigma: Bij een taxibedrijf veranderen de regels volledig. Een beller kan vragen om een rit naar “het ziekenhuis in Rotterdam.” Hier instrueert het schema de geovalidatie-API om dit Point of Interest te accepteren. Zijn er drie ziekenhuizen in Rotterdam, dan staat het schema de agent toe om dynamisch te verduidelijken welk ziekenhuis de beller bedoelt, in plaats van de invoer direct af te wijzen.
Zonder een schema dat deze grenzen definieert en de geovalidatie-API-integratie beheert, behandelt het LLM beide interacties precies hetzelfde — met mislukte API-calls en gefrustreerde klanten als gevolg.
Je API’s Beschermen met Strikte ID&V
Misschien wel de meest kritieke functie van het schema is het beschermen van je backendsystemen tegen de AI zelf én tegen kwaadwillende externe partijen.
Neem het Identificatie & Verificatie (ID&V) proces. Hoe identificeer je een klant op een veilige manier? Je kunt niet zomaar je CRM-API aan een LLM geven en zeggen dat het het maar moet uitzoeken. Een slecht beveiligd maar conversationeel vaardig LLM zou gemanipuleerd kunnen worden om je CRM te bruteforcen; door herhaalde verificatiepogingen te gebruiken om het huisnummer van een klant te achterhalen dat de aanvaller in eerste instantie helemaal niet kende.
Het schema voorkomt dit. Het fungeert als poortwachter en instrueert de AI expliciet dat eerst alle vereiste, geverifieerde datapunten bij de gebruiker moeten worden verzameld. Pas wanneer aan alle voorwaarden van het schema is voldaan, mag het systeem de API-call naar je backend uitvoeren.
De Balans tussen Vrijheid en Scripting
Zelfs als het om het gesprek zelf gaat, is controle cruciaal. We willen dat het LLM de vrijheid heeft om vloeiend te spreken en de unieke tone-of-voice van een merk aan te nemen bij het beantwoorden van complexe vragen.
Toch zijn er momenten in een klantreis die juridisch of merkgevoelig zijn. Het schema stelt ons in staat om elementen als de openingszin of compliance-disclaimers volledig hard te coderen. De AI mag geen eigen begroeting verzinnen. Het moet exact het wettelijk vereiste script voorlezen voordat het soepel terugschakelt naar natuurlijke taal voor de rest van het gesprek.
Architectuur Wint van Ruwe Intelligentie
De toekomst van spraakautomatisering draait niet om het vinden van een groter, slimmer model dat alles tegelijk doet. Het gaat om het bouwen van de juiste structurele grenzen rondom de modellen die we al hebben.
Door schema’s in te zetten, zorgen we ervoor dat de AI briljant is precies waar dat nodig is — terwijl de organisatie stevig aan het stuur blijft.
← Terug naar blog